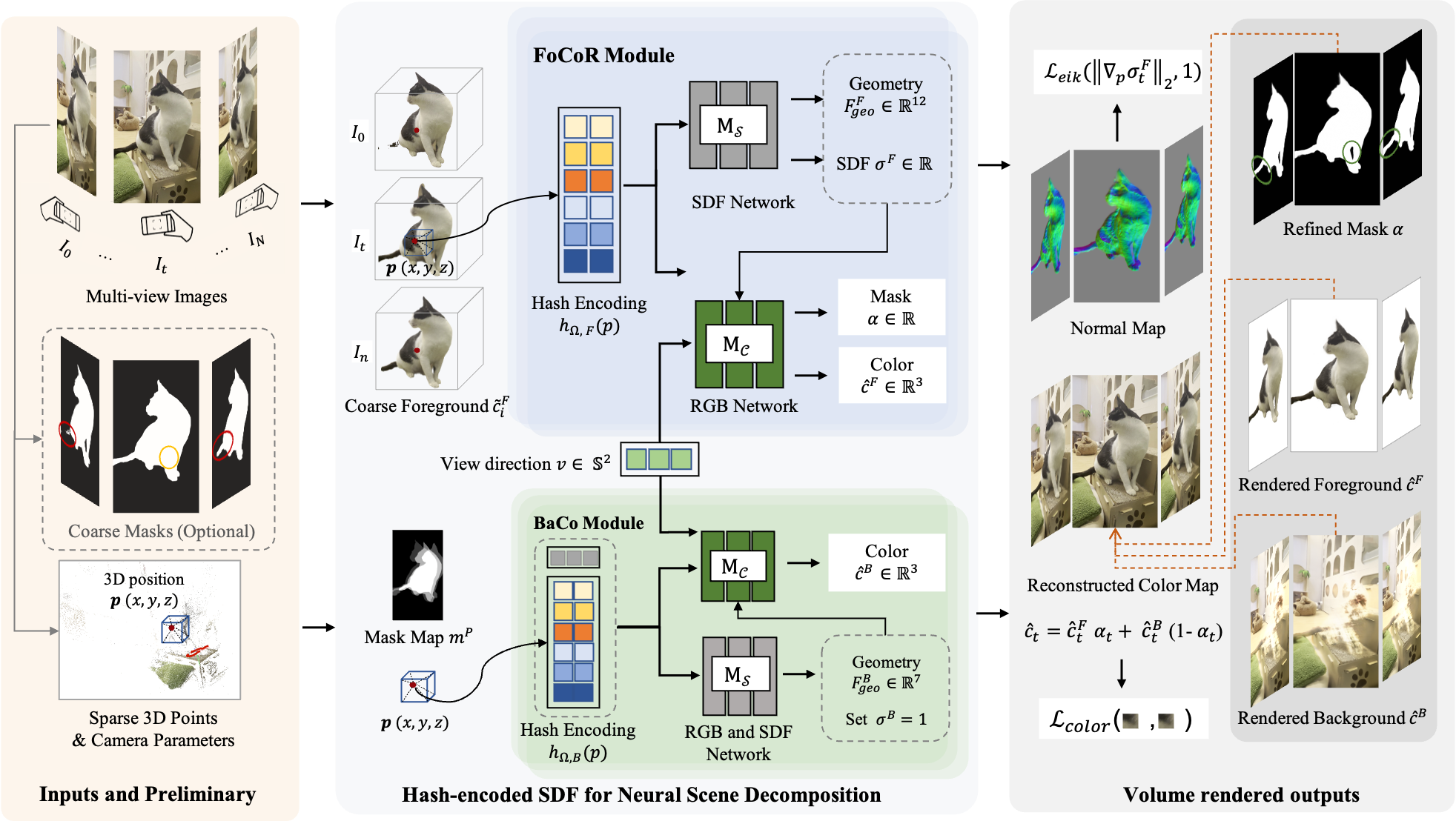
Framework. For the scene captured by N images, we use COLMAP and Mask-RCNN to get sparse 3D points and coarse object masks as co-inputs, and predict a dense, geometrical consistent object map, as well as a textural, completed background for each image. To tackle this challenging task by leveraging the existence of geometric consistency of the one-to-one dense mapping in 3D space, we decouple the scene into two complementary neural scene representation modules: a Foreground Consistent Representation (FoCoR) module and a Background Completion (BaCo) module. We build our scene representation modules upon the SDF-based neural surface representation, and incorporate multi-resolution hash encodings for training acceleration.
